First off, I would like to say I did not come up with these charts or rules myself. These are guidelines created by people who are far more adept at this. I just thought it would be useful to collate some of things I found for someone who is to trying to learn this skill set.
The first thing to recognize before working on any machine learning problem is to identify the type of problem you are trying to solve. Broadly speaking there are 4 main categories of machine learning:
- Supervised Learning – Supervised learning models require data scientists to provide the algorithm with data sets for input and parameters for output, as well as feedback on accuracy during the training process.
- Semi-supervised Learning – This approach teaches an algorithm through a mix of labeled and unlabeled data. This algorithm learns certain information through a set of labelled categories, suggestions and examples. Semi-supervised algorithms then create their own labels by exploring the data set or virtual world on their own, following a rough outline or some data scientist feedback.
- Unsupervised Learning – In unsupervised learning, data points have no labels associated with them. Instead, the goal of an unsupervised learning algorithm is to organize the data in some way or to describe its structure. Unsupervised learning groups data into clusters, as K-means does, or finds different ways of looking at complex data so that it appears simpler.
- Reinforcement Learning – These algorithms are based on a system of rewards and punishments learned through trial and error. The model is given a goal and seeks maximum reward for getting closer to that goal based on limited information and learns from its previous actions.
When choosing an algorithm, always take these aspects into account: accuracy, training time and ease of use. Many users put the accuracy first, while beginners tend to focus on algorithms they know best. When presented with a dataset, the first thing to consider is how to obtain results, no matter what those results might look like. Beginners tend to choose algorithms that are easy to implement and can obtain results quickly. This works fine, as long as it is just the first step in the process. Once you obtain some results and become familiar with the data, you may spend more time using more sophisticated algorithms to strengthen your understanding of the data, hence further improving the results.
This diagram below acts a quick guide and can be useful to determine which model is suitable for the problem you are trying to solve.
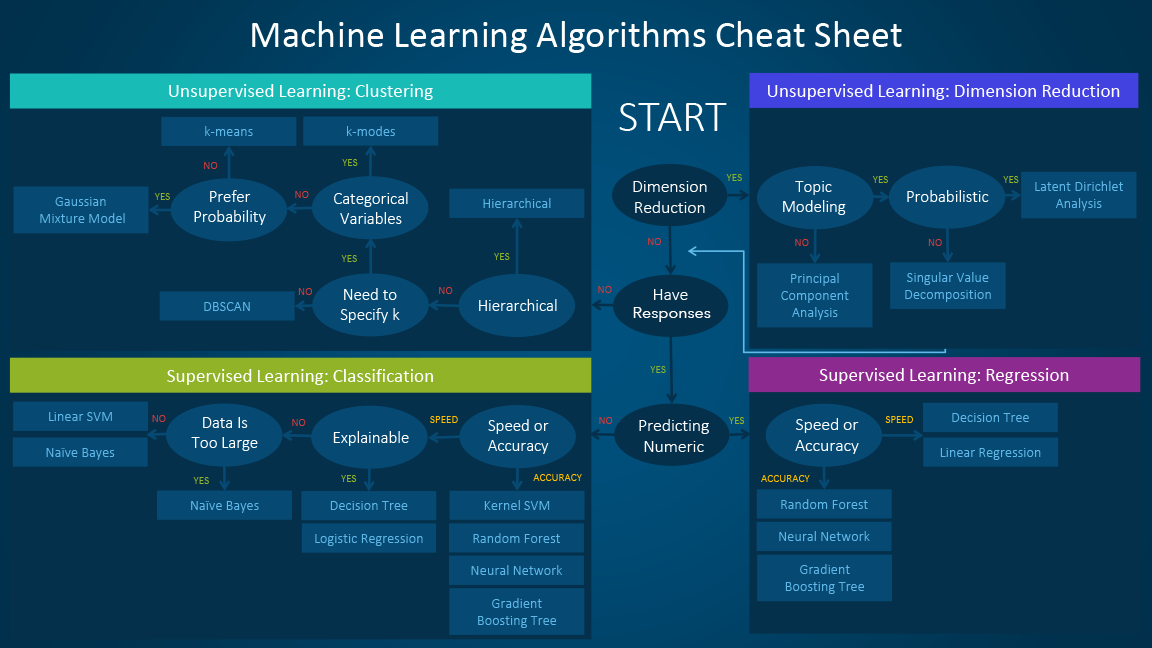
Here is another table that has a list of all frequently used models along with examples of use cases when they are generally used.
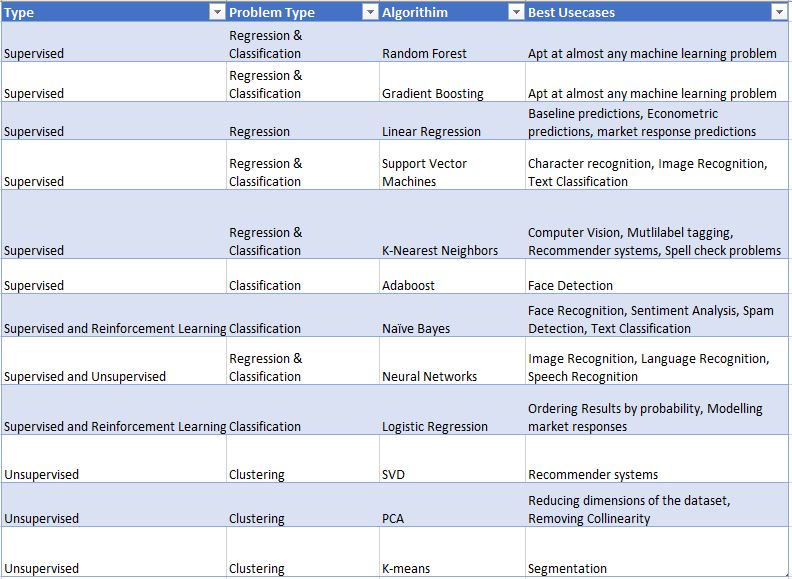
To summarize
- Define the problem. What problems do you want to solve?
- Use the above cheat sheets to build a basic model t familiarize yourself with the data and baseline results.
- Then try fine tuning your results by trying different models and choosing the best one.
