Text Classification of Disaster Tweets using NLP
This is my first foray into NLP and this challenge is perfect for someone like me who is just getting started with it. The task is to build a machine learning model that predicts which tweets are about real natural disasters and which are not. The training dataset has 7614 tweets that were hand classified.
For this task I decided to first develop a baseline NLP model using Bag of Words model to vectorize the sentences using CountVectorizer. Before we do that since the tweets are free form text which users enter we need to perform some preprocessing on our data to clean it up. A helper function can be easily written to perform the following
- remove urls
- remove emojis
- replace contractions with actual words (e.g. aren’t: are not, needn’t: need not)
- remove punctuations
- remove stop words
Once the tweets are cleaned the next step is to tokenize and lemmatize the text. Tokenize is when you break down the sentence as separate words in an list. This is done using word_tokenize method available in the nltk package. Lemmatization is the process of grouping together the different inflected forms of a word so they can be analyzed as a single item. Then the words are reconstructed together to form a single sentence.
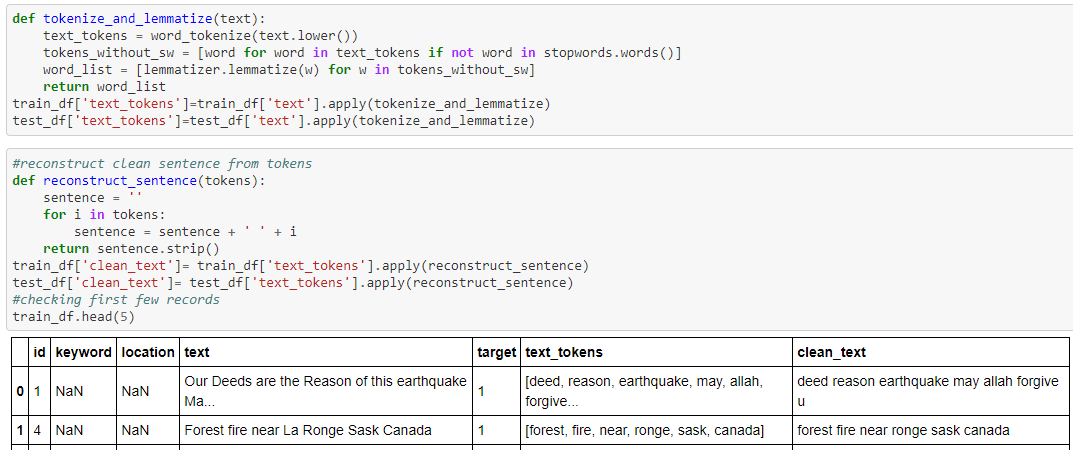
The training data is then vectorized using TfidVectorizer. A traditional scoring of word frequency leads to words which are very frequent to start dominating the document. This method called Term Frequency – Inverse Document Frequency rescales the frequency of words by how often they appear in all the documents. For e.g. words like ‘the’ that are frequent across all documents are penalized.
Another thing to consider is the order of words when they are vectorized. In a traditional bag of words model the order does not really affect the model. So we can use ngrams where counts of grouped words are vectorized. I used a bigram model where frequencies of 2 words are measured.
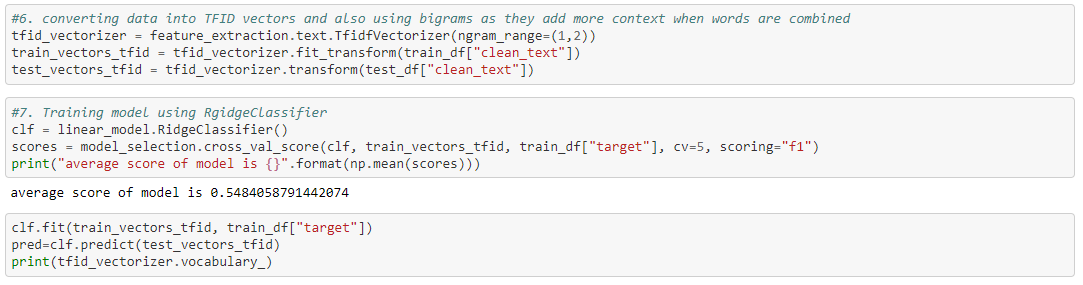
Once the data is vectorized we can use a simple RidgeClassifier to train our model. This model achieved an accuracy score of .8023 which was a good baseline for our first model.
Model using Word Embeddings and LSTM
Word Embeddings represents words as dense vectors which enables words which are similar in meaning to be able to have similar properties which greatly helps in text classification. I used a pretrained word embedding called GloVe which is available publicly.
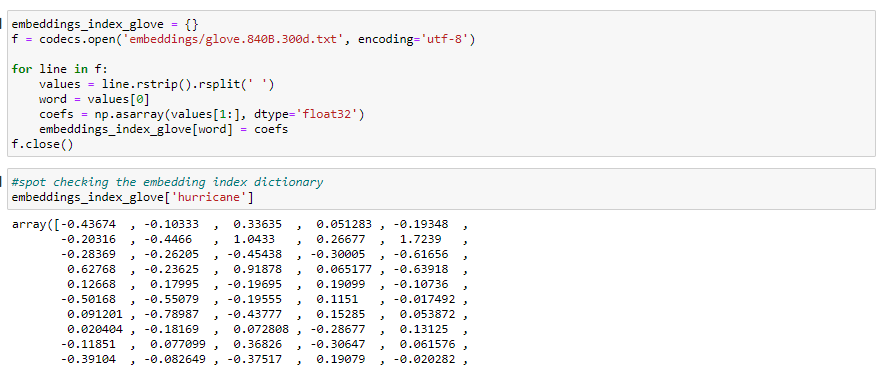
Before we build our model we also need to know what the dimensions of our embedding matrix should be. The pretrained dataset has 300 dimensions for each word. Analyzing the tweets data set we see most tweets are less than 20 words. So we can set the dimensions of the matrix as (300,20). Since all the tweets are not of same length we use the pad_sequences function so that all the data points in the training set have the same dimensions.
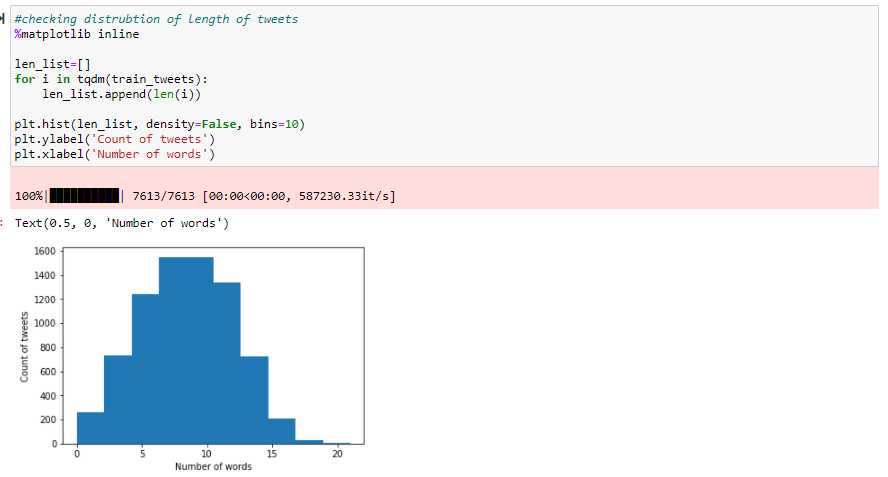
Embedding matrix will be used in embedding layer for the weight of each word in training data. It’s made by enumerating each unique word in the training dataset that existed in tokenized word index and locate the embedding weight with the weight from GloVe.

Long Short-Term Memory (LSTM)
Using Sequential method available in keras we can create a deep neural network. I created a model which has one Embedding Layer, 4 LSTM layers with 64 units and 1 LSTM layer with 32 units, a dense layer with a ReLU activation function and also a drop out layer to avoid overfitting. The model is then fit over 20 iterations to optimize our cost function and find out the best parameters for the model which can be used for prediction.
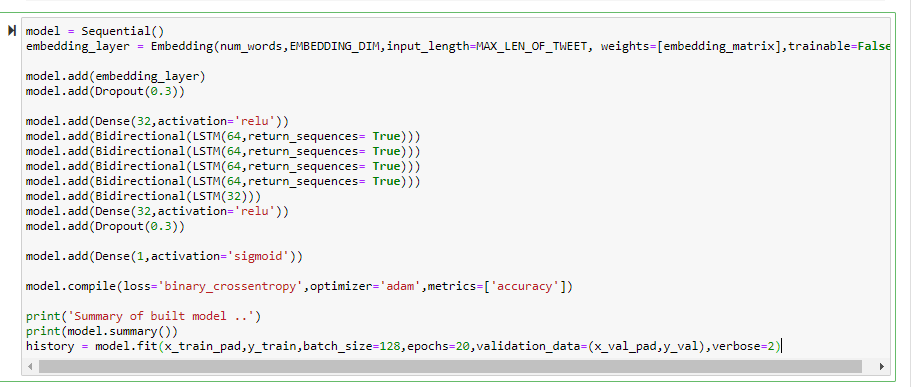
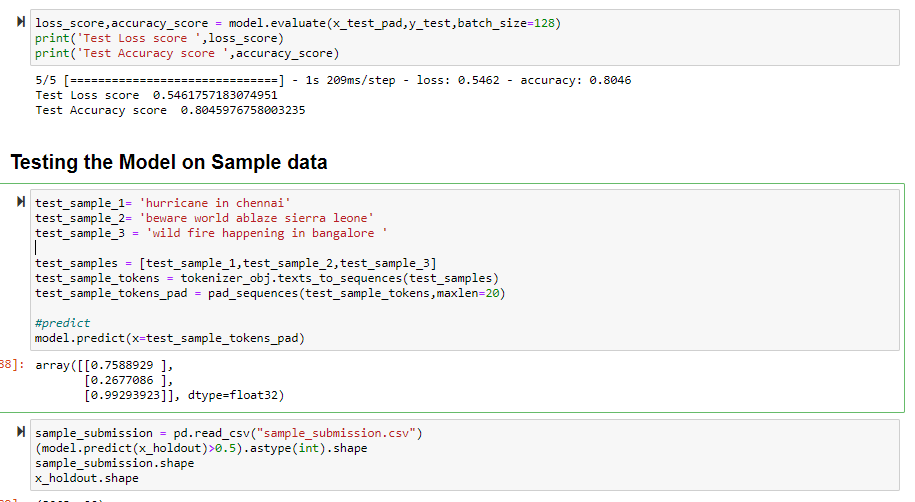
The model is evaluated on a holdout data set and it had a score of .804. I also tested the model to predict some random tweets to see how my model works on unseen data. Overall it did better than my bag of words model and I got a score of 0.8084 after submission which was an improvement from my previous model. There is scope for some hyperparameter tuning like considering how many units and layers to use in my deep learning model, what the keep probability should be in the dropout layer etc. I think tweaking some of those parameters can improve the results of my model.